Database Connection Pooling Explained — Why It Matters in 2026
In a production-grade application, every incoming request typically requires access to the database. The backend establishes a database connection, executes the query, returns the response, and then closes the connection.
While this flow works well under low traffic, it quickly becomes a bottleneck as traffic increases.
The Problem with Direct Database Connections
As concurrent requests grow, so does the number of database connections. Databases have strict limits on how many connections they can handle efficiently. Exceeding these limits leads to:
-
Increased latency
-
Connection exhaustion
-
Database crashes or throttling
-
Poor overall application performance
-
High CPU and memory usage on the database server
Opening and closing a database connection for every request is expensive and inefficient.
Enter Connection Pooling
Connection pooling solves this problem by reusing existing database connections instead of creating a new one for every request.
A connection pool maintains a fixed number of open connections and hands them out to requests as needed. Once a request finishes, the connection is returned to the pool instead of being closed.
This approach:
-
Limits the total number of active connections
-
Reduces connection overhead
-
Improves response times
-
Protects the database under high load
-
Makes your application more scalable and stable
How Connection Pooling Works
Think of it like a cab service:
- Instead of calling a new cab for every ride (creating new connection), the company keeps some cabs ready (pooled connections).
- After a ride, the cab returns to the pool and waits for the next customer.
The application talks to the pool, not directly to the database. The pool manages the real connections behind the scenes.
Popular Connection Pooling Solutions
There are well-known open-source tools that act as an intermediate layer between your application and the database:
-
PgBouncer
-
Pgpool
These tools expose a single connection endpoint to the application. Your backend connects to the pooler, and the pooler manages actual database connections behind the scenes.
Instead of:
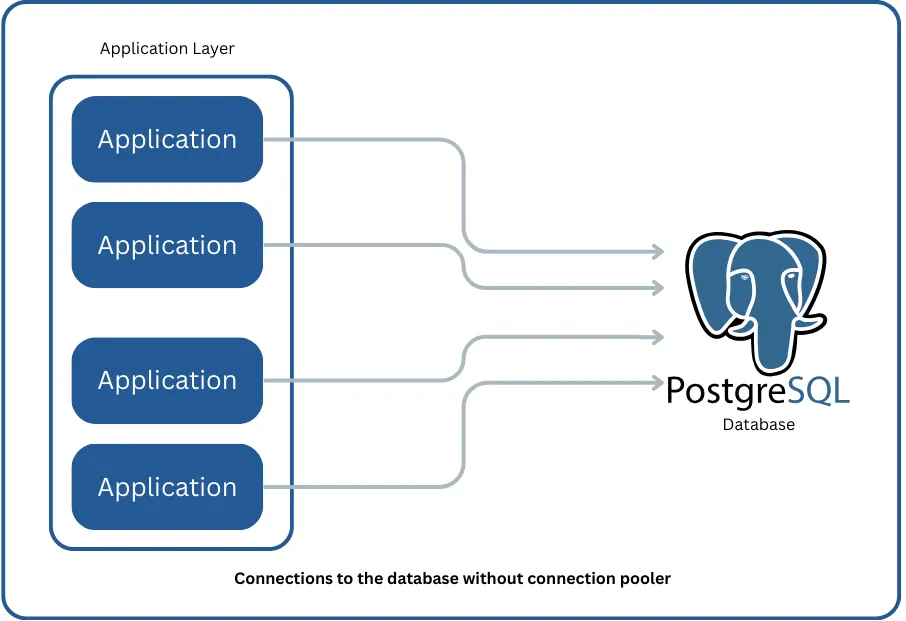
You get:
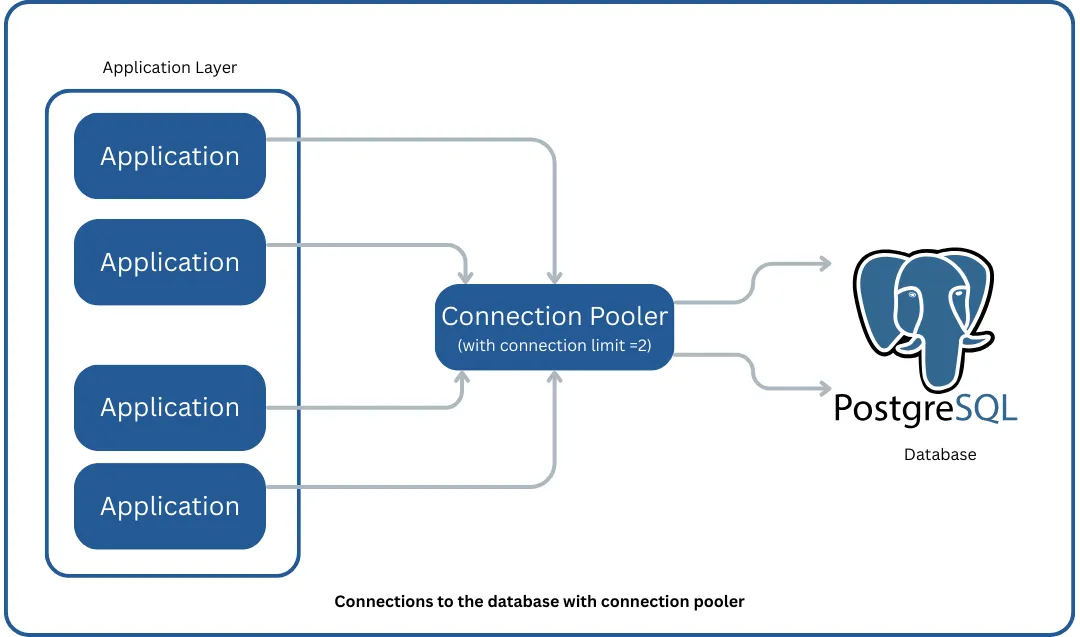
The Infrastructure Challenge
Using tools like PgBouncer or Pgpool requires:
-
Additional configuration
-
A separate instance or service
-
Control over database networking and settings
This setup works well for:
-
Self-hosted databases
-
Managed databases like Amazon RDS
However, things get trickier with AWS Aurora.
Aurora abstracts away many low-level database configurations, making it harder to deploy and manage traditional connection poolers alongside it.
AWS RDS Proxy to the Rescue
For Aurora and managed RDS environments, AWS provides AWS RDS Proxy.
RDS Proxy is a fully managed database proxy that:
-
Manages and pools database connections automatically
-
Protects the database during traffic spikes
-
Improves failover handling
-
Integrates seamlessly with IAM and AWS services
From the application’s perspective, it behaves just like a database endpoint—but behind the scenes, it efficiently reuses connections and keeps the database stable under load.
Final Thoughts
Connection pooling is not an optimization, it’s a necessity for scalable backend systems.
Whether you use open-source tools like PgBouncer or managed solutions like AWS RDS Proxy, the goal remains the same:
Reuse connections, reduce database load, and scale safely.
If you’re building high-traffic Django, FastAPI, or microservice-based systems, connection pooling should be part of your architecture from day one.